模板配置
部署完成后打开浏览器,访问 http://localhost:8080/spider 打开采集平台首页,点击导航栏的下拉菜单选择功能.

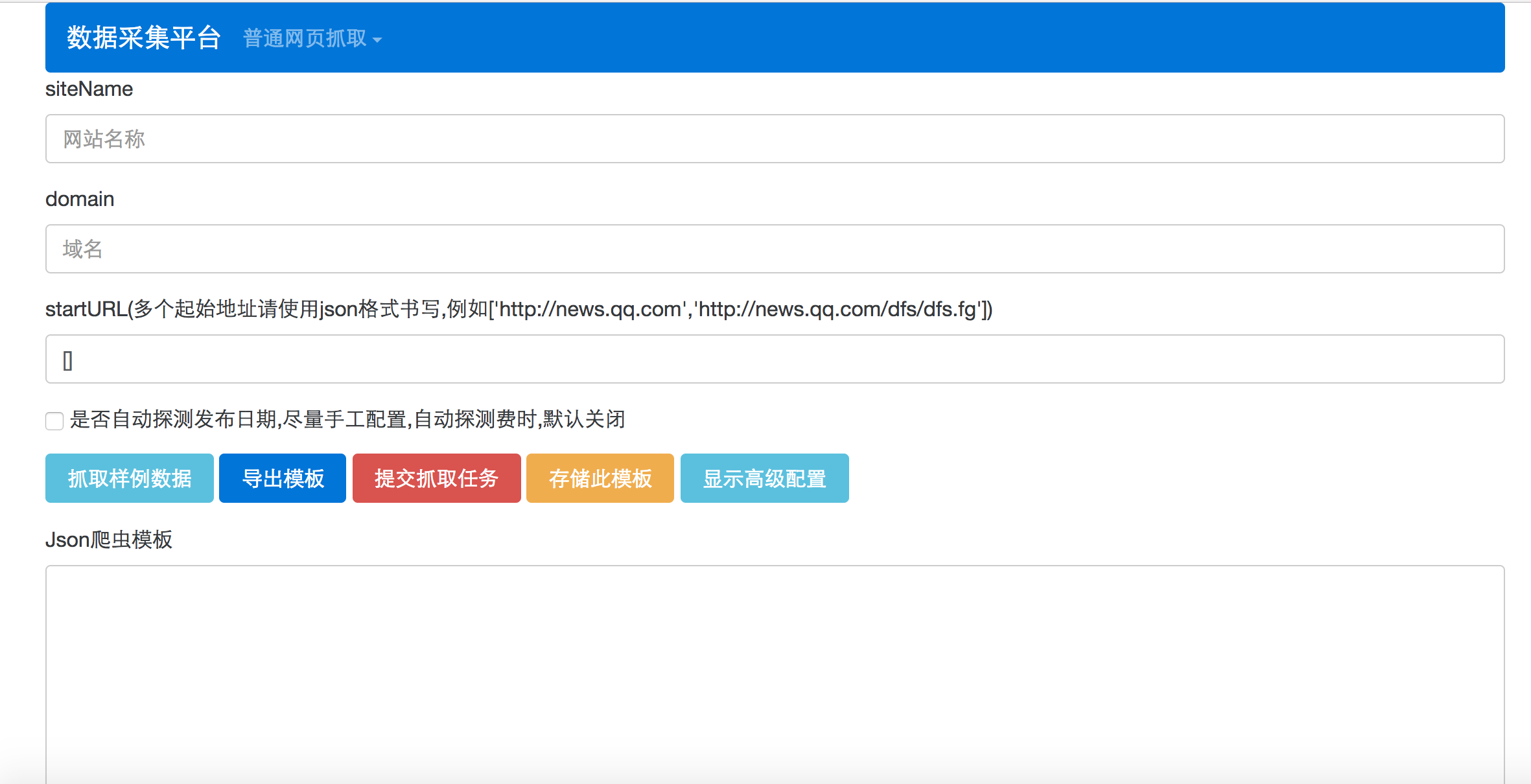
在导航栏的下拉菜单中点击 编辑模板 按钮,在这个页面中可完成一个爬虫的所有配置,具体每一个配置项的说明见每一个输入框的提示.
页面上只显示最基本的几个配置项,只要配置了这几个配置即可马上开始采集。如果需要更加详细的配置,则可以点击 显示高级配置 即可展开更多的配置项。
本平台在examples文件夹中给出了两个抓取腾讯新闻的示例,这两个一个是使用预定义的发布时间抓取规则,另外一个是使用系统自动探测文章的发布时间.
以预定义的爬虫模板为例,打开news.qq.com.json,将文件内容全部拷贝至爬虫模板编辑页面最下方的大输入框中,点击自动填充.
这时爬虫配置文件中的爬虫模板信息就被自动填充进上面的表格了.然后点击抓取样例数据按钮,稍等片刻即可在当前页面下方看到通过这个模板抓取的新闻数据了.
精准时间抽取就是在发布时间那一栏配置正则或者xpath,然后程序按照指定的抽取位置进行时间抽取。 自动探测就是由程序自己去识别哪里是发布时间,然后抽取时间。
如果模板配置的有问题,导致长时间卡在获取数据页面,请通过导航栏转至爬虫监控页面,将刚刚提交的这个抓取任务停止即可.
爬虫模板配置完成后,点击下面的 采集样例数据 按钮,稍等片刻即可在下方展示根据刚刚配置的模板抓取的数据,如果数据有误在上面的模板中进行修改,然后再次点击 采集样例数据 按钮即可重新抓取.
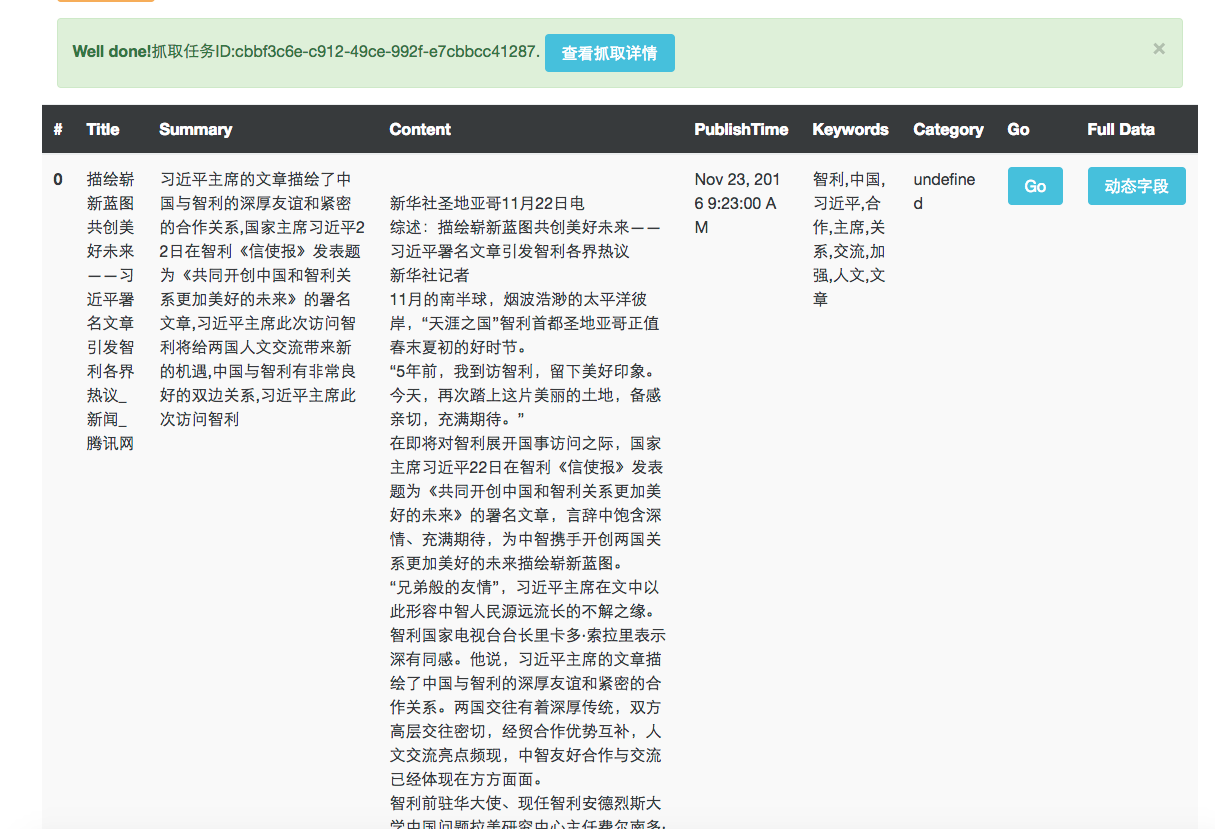
需要说明的是,这时页面下方显示的数据仅仅是为了验证模板配置的是否有问题,这些数据并没有进行存储。所以不论是数据管理页面,ES还是JSON文件中均没有任何数据。如果认为模板没有问题了,需要正式的开始采集数据,首先在maxGatherPage设置需要抓取的网页数量,然后点击下面的红色提交抓取任务按钮,这时才开始正式的进行数据采集。
注意,在对于爬虫模板没有完全的把握之前请勿选择爬虫模板下方的几个 是否网页必须有XXX 的配置项.以文章的标题为例,因为如果文章标题的配置项(即为title)配置有误,爬虫就无法抓取到网页的标题,如果这时再选中了 是否网页必须有标题 的话,就会导致爬虫无限制的进行抓取.

当模板配置完毕,即可点击下方的 导出模板 按钮,这时下方的大输入框中显示的Json格式的文字即为爬虫模板,可以将段文字保存到文本文件中,以便以后使用,也可以点击 存储此模板 对这个模板进行存储,以后可在本平台的 爬虫模板管理系统 中查找.